
Java基础整理
关键字
final (自己老是不太懂)
- 用在变量上,变量会变成常量 不可被修改
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
- 用在方法上,方法变成最终方法 不可被复写
- 用在类上,类变成最终类 不可被继承
String 就是一个最终类
static 静态
类方法
又称静态方法,用其只执行一次的特点,使用静态方法实现单例模式,生成单一对象,该对象可以被公共使用,减少内存操作,优化性能.
多个线程调用静态方法,是否会出现并发问题取决于,静态方法内部是否需要引用共享区内的静态变量。当线程调用静态方法时,都会创建一套临时变量,可见性是在这个线程内部,所以当多个线程调用静态方法时,并且这个静态方法没有引用外部静态变量的。不会有线程并发的问题。
工具类的特点是没有属性或属性是不会改变的
类属性
共享数据,可以在其他类直接访问类属性
静态代码块
静态块先于初始化块执行,而且只执行一次(同样适用于静态方法,静态属性。因为不论类被调用几次,类装载器只执行一次),可用于初始化静态属性(如读取配置文件,只需初始化一次即可)
例子:
public class Demo { |
变量
Java通过定义变量申请空间,并通过变量名改变存储的值
全局变量
- 又叫成员变量
- 作用域是整个类
- 可以不用默认赋值,系统会自动默认赋值,默认为null(Object)或者0(int…)
局部变量
- 方法内
- 作用域是定义位置到方法结束
- 不能不默认赋值,系统不会默认赋值
常量
- (全局)定义的时候必须赋值(final),不然系统会默认赋值还无法改变
- (局部)定义发时候可以不赋值,但是使用的时候必须赋值
运算符
算术运算符
- + 加法 - 相加运算符两侧的值 A + B 等于 30
- - 减法 - 左操作数减去右操作数 A – B 等于 -10
- * 乘法 - 相乘操作符两侧的值 A * B等于200
- / 除法 - 左操作数除以右操作数 B / A等于2
- % 取余 - 左操作数除以右操作数的余数 B%A等于0
- ++ 自增: 操作数的值增加1 B++ 或 ++B 等于 21(区别详见下文)
- – 自减: 操作数的值减少1
注意 ++i 和 i++ 的关系,主要是 System.out.println(i++); 先输出 再+1,–i同理.
关系运算符
- == 检查如果两个操作数的值是否相等,如果相等则条件为真。 (A == B)为假。
- != 检查如果两个操作数的值是否相等,如果值不相等则条件为真。 (A != B) 为真。
- > 检查左操作数的值是否大于右操作数的值,如果是那么条件为真。 (A> B)为假。
- < 检查左操作数的值是否小于右操作数的值,如果是那么条件为真。 (A <B)为真。
->= 检查左操作数的值是否大于或等于右操作数的值,如果是那么条件为真。 (A> = B)为假。 - <= 检查左操作数的值是否小于或等于右操作数的值,如果是那么条件为真。 (A <= B)为真。
字符串的比较是对象的值比较要用 .equals()方法;直接 == 是比较内存里的地址
Integer a = 14; |
在java.lang.Integer 是有缓存的 Integer.valueOf不会创建新的对象很有意思 而是直接返回 缓存中的对象
/** |
位运算符
- & 如果相对应位都是1,则结果为1,否则为0 (A&B),得到12,即0000 1100
| 如果相对应位都是 0,则结果为 0,否则为 1 (A | B)得到61,即 0011 1101 - ^ 如果相对应位值相同,则结果为0,否则为1 (A ^ B)得到49,即 0011 0001
- 〜 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 (〜A)得到-61,即1100 0011
- << 按位左移运算符。左操作数按位左移右操作数指定的位数。 A << 2得到240,即 1111 0000
- >> 按位右移运算符。左操作数按位右移右操作数指定的位数。 A >> 2得到15即 1111
- >>> 按位右移补零操作符。左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充。 A>>>2得到15即0000 1111
int a = 60; /* 60 = 0011 1100 */ |
逻辑运算符
- && 称为逻辑与运算符。当且仅当两个操作数都为真,条件才为真。 (A && B)为假。
- | | 称为逻辑或操作符。如果任何两个操作数任何一个为真,条件为真。 (A | | B)为真。
! 称为逻辑非运算符。用来反转操作数的逻辑状态。如果条件为true,则逻辑非运算符将得到false。 !(A && B)为真。
三元判断 i = t > 0 ? 1 : 0 (t>0时i=1,否则i=0)
从右向左运算,如a?b:c?d:e将按a?b:(c?d:e)执行(ac为返回true或false的表达式)
数据类型
8大基本数据类型
- byte 1字节 8bit 00000001
- short 2字节
- int 4字节
long 8字节
float 4字节
double 8字节
char 2字节
- boolean
boolean 由虚拟机决定 实际上只需要1bit 一位就能定义,在虚拟机里面是4字节来表示的(int) 主流32位的处理器(CPU)来说,一次处理数据是32位
类与对象
对象-万物皆对象
类
类是对现实生活中一类具有共同特征的事物的抽象。Java就是有相同属性和相同方法的的对象的抽象
- 类的属性(全局变量)
由基本类型(还有字符串)和其他引用对象类型(其他的类或者接口)组成
- 类的方法
描述对象的行为
类之间的关系
关联 (组合,聚合)
泛化 (继承)
依赖 (接口,实现)
依赖:类B作为参数被类A在某个method方法中,A依赖B
关联:被关联类B以类的属性形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量
聚合:整体与部分是可分的,代码层面,和关联关系是一致的,只能从语义级别来区分
组合:整体与部分之间是不可分的,代码层面,和关联关系是一致的,只能从语义级别来区分
- 类图
面向对象的特征
抽象
忽略一个主题中与当前目标无关的东西,专注的注意与当前目标有关的方面。(就是把现实世界中的某一类东西,提取出来,用程序代码表示,抽象出来的一般叫做类或者接口)。抽象并不打算了解全部问题,而是选择其中的一部分,暂时不用部分细节。抽象包括两个方面,一个数据抽象,而是过程抽象。
数据抽象 –>表示世界中一类事物的特征,就是对象的属性。比如鸟有翅膀,羽毛等(类的属性)
过程抽象 –>表示世界中一类事物的行为,就是对象的行为。比如鸟会飞,会叫(类的方法)
- 具有相同属性和方法可以进行抽象
- 对象抽象到类,子类抽象到父类
封装
封装是面向对象的特征之一,是对象和类概念的主要特性。封装就是把过程和数据包围起来,对数据的访问只能通过已定义的界面。如私有变量,用set,get方法获取。
封装保证了模块具有较好的独立性,使得程序维护修改较为容易。对应用程序的修改仅限于类的内部,因而可以将应用程序修改带来的影响减少到最低限度。
将对象的属性,和实现方式进行隐藏 实现封装:属性私有化,提供两个公有方法getter setter操作属性
好处
- 提高数据的安全性 对于不想改的数据只提供get方法不提供set方法,对于修改有限制的可以写在set方法内
- 允许类创建者修改内部结构而不影响类使用者的使用。
- 类的使用者就不能接触和改变类的实现细节,所以原创者就不用担心自己的作品会收到非法篡改,可确保他们不会对其他人造成影响。
继承
一种联结类的层次模型,并且允许和鼓励类的重用,提供一种明确表达共性的方法。对象的一个新类可以从现有的类中派生,这个过程称为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),原始类称为新类的基类(父类)。派生类可以从它的父类哪里继承方法和实例变量,并且类可以修改或增加新的方法使之更适合特殊的需要。因此可以说,继承为了重用父类代码,同时为实现多态性作准备。
- 子类可以抽象父类的方法
- 子类有且仅有一个父类,如果没有指定默认是Object,Object是所有类的父类
子类继承父类中所有的public和protected类型的属性和成员方法(除了父类的构造函数,子类无法直接使用这个函数,即使它为public)
- 子类不能继承父类的私有属性,但是如果子类中公有的方法影响到了父类私有属性,那么私有属性是能够被子类使用的。
- 如果父子类在同一包中,子类也继承父类default的属性和方法,否则不能
- private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的属性以及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
default:同包类访问,当前包下的子包中的类,也不可访问;
protected: 也是同包类可访问,当前包下的子包中的类,也不可访问;但子类(不论是否同包)都可访问;
public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不仅可以跨类访问,而且允许跨包访问。 - 子类继承父类之后,子类所有的构造方法(无论无参有参)都会默认调用父类中的无参构造方法(除非使用super(参数),这个会调用父类对应的有参构造函数)
方案1:子类也写一个参数相同的构造方法,并在构造方法内写super(参数)这行代码
方案2:子类不写带super(参数)的构造函数(可以写带setter()的有参构造函数),父类再写一个无参的构造函数 - super关键字(this代表自己,super代表父类)
当父子类具有相同的方法时,会采用就近原则调用(全局/局部变量也适用,这也是为什么要在类中使用this的原因),若想在子类中调用父类的方法,使用super.method()(即子类重写父类方法的时候(重写才会有相同的方法)才有可能用到super)
子类不能直接调用父类有参构造方法(默认调用无参的),若想调用父类有参的构造函数要在子类有参构造函数里使用super(参数),调用语句必须是第一句
- 初始化顺序:先静态后非静态,先父类后子类
- java只支持单一继承,多重继承要利用接口来实现。(多扩展通过接口)
多态
多态是指允许不同类的对象对同一消息做出响应。多态性包括参数化多态性和包含多态性。多态性语言具有灵活/抽象/行为共享/代码共享的优势,很好的解决了应用程序函数同名问题。总的来说,方法的重写,重载与动态链接构成多态性。Java引入多态的概念原因之一就是弥补类的单继承带来的功能不足。
同一对象/属性/方法的不同表现形式
动态链接 –>对于父类中定义的方法,如果子类中重写了该方法,那么父类类型的引用将调用子类中的这个方法,这就是动态链接。
- 编译时候 同一个方法 传入参数不同=不同方法
- 运行时候 定义父类 实现由子类(不同)实现
在父子类中,子类重写父类的方法,并在外面调用该方法时(但不知道哪个子类调用,传入参数不同则调用不同),可以使用多态优化。其他情况还是要用instanceof人工判断
数组
声明方式
确定情况下: int[] arr = new int[]{1,2,3}; // 不能填10
不确定情况下: int[] arr = new int[10]; // 10不能为不填
数组在堆中被分配的是连续的空间(栈中只存数组第一个内存空间的地址)
int[10],直接开10个空间给你
集合
集合是用来存储数据的容器,其API包含在java.util包中
Collection接口
特殊的的LinkedList 即实现了List接口也实现了Queue 所有有双重功能而ArrayList 只实现了List的接口
List
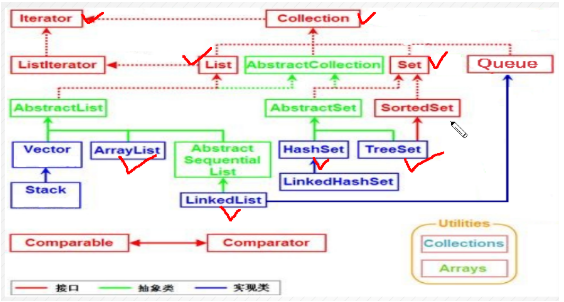
Vector (顺序线性存储结构)
- 顺序线性存储结构
- 动态数组安全
- 线程安全
- 查询,增加,删除都很慢
- 默认扩充为当前容量的2倍
动态数组并不是真正意义上的动态的内存,而是一块连续的内存,当添加新的元素时,容量已经等于当前的大小的时候(存不下了),执行下面3步:
1.重新开辟一块大小为当前容量两倍的数组
2.把原数据拷贝过去
3.释放掉旧的数组
- ArrayList (顺序线性存储结构)
ArrayList的出现替代了Vector,同样顺序线性存储结构,动态数组实现,但线程不安全,查询效率高,增删效率低,默认扩充为原先的1.5倍
- LinkedList (链式线性存储结构)
链式线性存储结构,双向链表实现,线程不安全,增删效率高,查询效率低
Set
HashSet (无序不可重复)
TreeSet(有序(大小顺序,不是下标顺序)
不可重复的数据:因为重写了SortedSet接口)。所以若存入不能按大小排序的对象(如Dog类的实例)将会报错,则此时需要使用排序器(内部/外部)使其能够排序
TreeSet<A> s = new TreeSet<>((o1, o2) -> o2.getIndex() - o1.getIndex()); |
遍历方式
List for循环 Iterator迭代器 foreach循环
Set Iterator迭代器 foreach循环
Map接口
基于键值对映射,key不可以重复,value可以重复。插入相同的key会进行覆盖而不是抛弃
优点:便于查询 缺点:遍历较慢
HashMap
Key特性和HashSet一样无序
JDK1.7时代
总结:
底层实现:数组和链表
Hash算法:index = HashCode(Key) & (Length - 1)
不用取模运算的原因是取模运算虽然简单但是效率很低,所以使用了位运算的方式。
- 默认长度16: 长度默认为2的幂
每次自动扩容或手动初始化时,长度必须是2的幂(原因就是由上述Hash算法决定的,只有Length等于2的幂上述Hash算法才能均匀分布)。16(Length)-1 = 15 二进制为 1111, 32(Length)-1 = 31 二进制为 11111;
- HashMap.Size(HashMap的当前长度) >= Capacity(HashMap的当前容量) * LoadFactor(负载因子,默认为0.75f)
Resize包含扩容和ReHash两个步骤,扩容就是新建一个大小为原先两倍的数组,Rehash就是调用transfer方法将原数组元素按照新的数组大小重新计算索引并迁移过去。
遇到的问题
- 数据覆盖
数据覆盖问题:并发执行put操作时可能发生数据覆盖,假设两个线程A、B都在进行put操作,虽然值不一样但是hash函数计算出的插入下标是相同的,当线程A执行完hash计算后由于时间片耗尽导致被挂起,而线程B得到时间片完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所以此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了。
- 死循环
Resize导致死循环(和数据丢失?)的问题:在调用transfer方法迁移的过程中使用了头插法导致了链表被翻转,这可能和之前被挂起的线程的指针指向出现形成链表环的可能。当形成链表环后,如果调用get查找一个不存在的key,而这个key的Hash结果恰好是存在链表环的那个,程序将会进入死循环;(并且一旦形成链表环,该链表环之后的元素没办法被迁移也就丢失了?)。链接
- JDK1.8优化
总结:
- 底层实现
JDK1.7是数组+ 单链表的数据结构。JDK1.8是数组+链表/红黑树的数据结构,当数组容量未达到64时,和JDK1.7一样以2倍进行扩容,超过64之后再次插入元素时若对应的链表元素数量大于8就将该链表转换为红黑树(利用红黑树的特性,可以使get/put的操作时间复杂度最差为O(log n),提高了效率),但如果红黑树中的元素个数小于6就会重新还原为链表
- 扩容 (直接计算)
JDK1.7扩容时仍采用HashCode(Key) & (Length - 1)的方法计算扩容后的位置,而JDK1.8则是通过判断Hash值的新增参与位是0还是1直接计算出扩容后的位置。
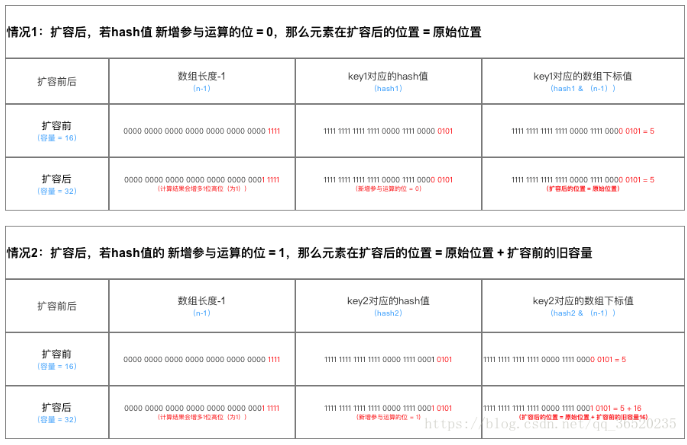
- 优化 (多线程数据覆盖依然存在)
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,避免Resize时因为链表翻转出现链表环导致死循环的问题,解决了Resize导致死循环(和数据丢失?)的问题:移除了transfer方法,直接在resize函数中完成了数据迁移,并且是采用尾插法迁移元素保证链表顺序,杜绝了链表环形成的可能。
TreeMap
Key特性同TreeSet一样 自动按大小排序
Hashtable
HashMap线程不安全,Hashtable线程安全;
HashMap效率高于Hashtable(因为为了保证线程安全Hashtable的实现方法里面都添加了synchronized关键字)
HashMap的key和value允许null值,但只能有一个key为null
Hashtable的key和value不允许为null值HashMap把Hashtable的contains方法去掉了,只保留containsvalue和containsKey
哈希值的使用不同:
Hashtable直接使用对象的hashCode
HashMap重新计算hash值。
线程安全的使用HashMap
Hashtable: 使用synchronized来锁住整个table来保证线程安全,所有线程竞争同一把锁,效率低
Collectionis的内部类Synchronized Map,也是通过对读写进行加锁操作来保证线程的安全,效率也是硬伤
ConcurrentHashMap (用这个吧)
JDK8之前,使用segment即锁分段技术(首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问)来保证线程安全,降低了锁的粒度,除非两个线程同时操作一个segement才会争抢锁。
JDK8后,摒弃了Segment,利用CAS+Synchronized来保证并发安全,将锁的粒度进一步细化,每一个Node对象作为了一个锁,除非两个线程同时操作一个Node,(注意是一个Node而不是一个Node链表)那么才会争抢同一把锁。支持的并发更多,性能更高。
内存模型中,栈存放基本类型数据和引用类型数据的地址,堆存放引用类型数据

